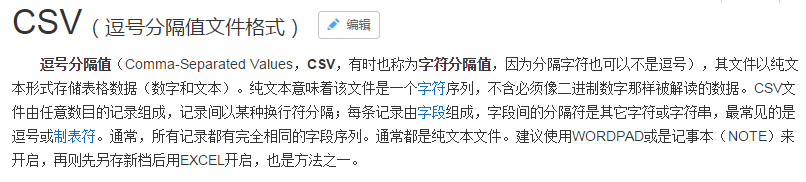
以前导出总是用POI导出为Excel文件,后来当我了解到CSV以后,我发现速度飞快。
如果导出的数据不要求格式、样式、公式等等,建议最好导成CSV文件,因为真的很快。
虽然我们可以用Java再带的文件相关的类去操作以生成一个CSV文件,但事实上有好多第三方类库也提供了类似的功能。
这里我们使用apache提供的commons-csv组件
Commons CSV
文档在这里
http://commons.apache.org/proper/commons-csv/
http://commons.apache.org/proper/commons-csv/user-guide.html
先看一下具体用法

@Test public void testWrite() throws Exception { FileOutputStream fos = new FileOutputStream("E:/cjsworkspace/cjs-excel-demo/target/abc.csv"); OutputStreamWriter osw = new OutputStreamWriter(fos, "GBK"); CSVFormat csvFormat = CSVFormat.DEFAULT.withHeader("姓名", "年龄", "家乡"); CSVPrinter csvPrinter = new CSVPrinter(osw, csvFormat); // csvPrinter = CSVFormat.DEFAULT.withHeader("姓名", "年龄", "家乡").print(osw); for (int i = 0; i < 10; i++) { csvPrinter.printRecord("张三", 20, "湖北"); } csvPrinter.flush(); csvPrinter.close(); } @Test public void testRead() throws IOException { InputStream is = new FileInputStream("E:/cjsworkspace/cjs-excel-demo/target/abc.csv"); InputStreamReader isr = new InputStreamReader(is, "GBK"); Reader reader = new BufferedReader(isr); CSVParser parser = CSVFormat.EXCEL.withHeader("name", "age", "jia").parse(reader); // CSVParser csvParser = CSVParser.parse(reader, CSVFormat.DEFAULT.withHeader("name", "age", "jia")); List<CSVRecord> list = parser.getRecords(); for (CSVRecord record : list) { System.out.println(record.getRecordNumber() + ":" + record.get("name") + ":" + record.get("age") + ":" + record.get("jia")); } parser.close(); } /** * Parsing an Excel CSV File */ @Test public void testParse() throws Exception { Reader reader = new FileReader("C:/Users/Administrator/Desktop/abc.csv"); CSVParser parser = CSVFormat.EXCEL.parse(reader); for (CSVRecord record : parser.getRecords()) { System.out.println(record); } parser.close(); } /** * Defining a header manually */ @Test public void testParseWithHeader() throws Exception { Reader reader = new FileReader("C:/Users/Administrator/Desktop/abc.csv"); CSVParser parser = CSVFormat.EXCEL.withHeader("id", "name", "code").parse(reader); for (CSVRecord record : parser.getRecords()) { System.out.println(record.get("id") + "," + record.get("name") + "," + record.get("code")); } parser.close(); } /** * Using an enum to define a header */ enum MyHeaderEnum { ID, NAME, CODE; } @Test public void testParseWithEnum() throws Exception { Reader reader = new FileReader("C:/Users/Administrator/Desktop/abc.csv"); CSVParser parser = CSVFormat.EXCEL.withHeader(MyHeaderEnum.class).parse(reader); for (CSVRecord record : parser.getRecords()) { System.out.println(record.get(MyHeaderEnum.ID) + "," + record.get(MyHeaderEnum.NAME) + "," + record.get(MyHeaderEnum.CODE)); } parser.close(); } private List<Map<String, String>> recordList = new ArrayList<>(); @Before public void init() { for (int i = 0; i < 5; i++) { Map<String, String> map = new HashMap<>(); map.put("name", "zhangsan"); map.put("code", "001"); recordList.add(map); } } @Test public void writeMuti() throws InterruptedException { ExecutorService executorService = Executors.newFixedThreadPool(3); CountDownLatch doneSignal = new CountDownLatch(2); executorService.submit(new exprotThread("E:/0.csv", recordList, doneSignal)); executorService.submit(new exprotThread("E:/1.csv", recordList, doneSignal)); doneSignal.await(); System.out.println("Finish!!!"); } class exprotThread implements Runnable { private String filename; private List<Map<String, String>> list; private CountDownLatch countDownLatch; public exprotThread(String filename, List<Map<String, String>> list, CountDownLatch countDownLatch) { this.filename = filename; this.list = list; this.countDownLatch = countDownLatch; } @Override public void run() { try { CSVPrinter printer = new CSVPrinter(new FileWriter(filename), CSVFormat.EXCEL.withHeader("NAME", "CODE")); for (Map<String, String> map : list) { printer.printRecord(map.values()); } printer.close(); countDownLatch.countDown(); } catch (IOException e) { e.printStackTrace(); } } }
CSV与EXCEL
/** * 测试写100万数据需要花费多长时间 */ @Test public void testMillion() throws Exception { int times = 10000 * 10; Object[] cells = {"满100减15元", "100011", 15}; // 导出为CSV文件 long t1 = System.currentTimeMillis(); FileWriter writer = new FileWriter("G:/test1.csv"); CSVPrinter printer = CSVFormat.EXCEL.print(writer); for (int i = 0; i < times; i++) { printer.printRecord(cells); } printer.flush(); printer.close(); long t2 = System.currentTimeMillis(); System.out.println("CSV: " + (t2 - t1)); // 导出为Excel文件 long t3 = System.currentTimeMillis(); XSSFWorkbook workbook = new XSSFWorkbook(); XSSFSheet sheet = workbook.createSheet(); for (int i = 0; i < times; i++) { XSSFRow row = sheet.createRow(i); for (int j = 0; j < cells.length; j++) { XSSFCell cell = row.createCell(j); cell.setCellValue(String.valueOf(cells[j])); } } FileOutputStream fos = new FileOutputStream("G:/test2.xlsx"); workbook.write(fos); fos.flush(); fos.close(); long t4 = System.currentTimeMillis(); System.out.println("Excel: " + (t4 - t3)); }

Maven依赖
<dependencies> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-csv</artifactId> <version>1.5</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>3.17</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>3.17</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency> </dependencies>
最后,刚才的例子中只写了3个字段,100万行,生成的CSV文件有十几二十兆,太多的话建议分多个文件打包下周,不然想象一个打开一个几百兆的excel都费劲。
欢迎各位转载,但必须在文章页面中给出作者和原文链接!

发表评论 取消回复