接着上面一篇对爬虫需要的java知识,这一篇目的就是在于网络爬虫的实现,对数据的获取,以便分析。
----->
目录:
1、爬虫原理
2、本地文件数据提取及分析
3、单网页数据的读取
4、运用正则表达式完成超连接的连接匹配和提取
5、广度优先遍历,多网页的数据爬取
6、多线程的网页爬取
7、总结
爬虫实现原理
网络爬虫基本技术处理
网络爬虫是数据采集的一种方法,实际项目开发中,通过爬虫做数据采集一般只有以下几种情况:
1) 搜索引擎
2) 竞品调研
3) 舆情监控
4) 市场分析
网络爬虫的整体执行流程:
1) 确定一个(多个)种子网页
2) 进行数据的内容提取
3) 将网页中的关联网页连接提取出来
4) 将尚未爬取的关联网页内容放到一个队列中
5) 从队列中取出一个待爬取的页面,判断之前是否爬过。
6) 把没有爬过的进行爬取,并进行之前的重复操作。
7) 直到队列中没有新的内容,爬虫执行结束。
这样完成爬虫时,会有一些概念必须知道的:
1) 深度(depth):一般来说,表示从种子页到当前页的打开连接数,一般建议不要超过5层。
2) 广度(宽度)优先和深度优先:表示爬取时的优先级。建议使用广度优先,按深度的层级来顺序爬取。
Ⅰ 在进行网页爬虫前,我们先针对一个飞机事故失事的文档进行数据提取的练习,主要是温习一下上一篇的java知识,也是为了下面爬虫实现作一个热身准备。
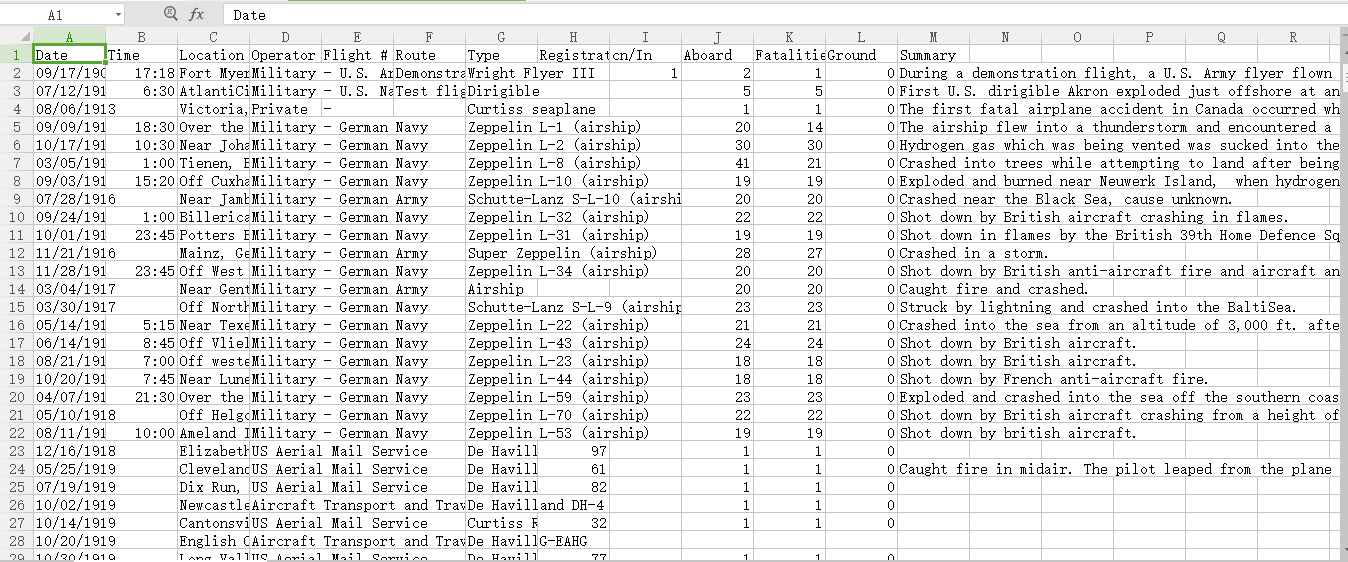
首先分析这个文档, ,关于美国历来每次飞机失事的数据,包含时间地点、驾驶员、死亡人数、总人数、事件描述,一共有12列,第一列是标题,下面一共有5268条数据。
,关于美国历来每次飞机失事的数据,包含时间地点、驾驶员、死亡人数、总人数、事件描述,一共有12列,第一列是标题,下面一共有5268条数据。
现在我要对这个文件进行数据提取,并实现一下分析:
根据飞机事故的数据文档来进行简单数据统计。
1) 哪年出事故次数最多
2) 哪个时间段(上午 8 – 12,下午 12 – 18,晚上 18 – 24,凌晨 0 – 8 )事故出现次数最多。
3) 哪年死亡人数最多
4)哪条数据的幸存率最高。

代码实现:(一切知识从源码获取!)

1 package com.plane; 2 3 import java.io.*; 4 import java.text.ParseException; 5 import java.text.SimpleDateFormat; 6 import java.util.*; 7 /** 8 * 飞机事故统计 9 * @author k04 10 *sunwengang 11 *2017-08-11 12 */ 13 public class planeaccident { 14 //数据获取存取链表 15 private static List<String> alldata=new ArrayList<>(); 16 17 public static void main(String args[]){ 18 getData("飞行事故数据统计_Since_1908.csv"); 19 alldata.remove(0); 20 //System.out.println(alldata.size()); 21 //死亡人数最多的年份 22 MaxDeadYear(); 23 //事故发生次数最多的年份 24 MaxAccidentsYear(); 25 //事故各个时间段发生的次数 26 FrequencyPeriod(); 27 //幸村率最高的一条数据 28 MaximumSurvival(); 29 } 30 31 /** 32 * 从源文件爬取数据 33 * getData(String filepath) 34 * @param filepath 35 */ 36 public static void getData(String filepath){ 37 File f=new File(filepath); 38 //行读取数据 39 try{ 40 BufferedReader br=new BufferedReader(new FileReader(f)); 41 String line=null; 42 while((line=(br.readLine()))!=null){ 43 alldata.add(line); 44 } 45 br.close(); 46 }catch(Exception e){ 47 e.printStackTrace(); 48 } 49 } 50 /** 51 * 记录每年对应的死亡人数 52 * @throws 53 * 并输出死亡人数最多的年份,及该年死亡人数 54 */ 55 public static void MaxDeadYear(){ 56 //记录年份对应死亡人数 57 Map<Integer,Integer> map=new HashMap<>(); 58 //时间用date显示 59 SimpleDateFormat sdf=new SimpleDateFormat("MM/dd/YYYY"); 60 //循环所有数据 61 for(String data:alldata){ 62 //用逗号将数据分离,第一个是年份,第11个是死亡人数 63 String[] strs=data.split(","); 64 if(strs[0]!=null){ 65 //获取年份 66 try { 67 Date date=sdf.parse(strs[0]); 68 int year=date.getYear(); 69 //判断map中是否记录过这个数据 70 if(map.containsKey(year)){ 71 //已存在,则记录数+该年死亡人数 72 map.put(year, map.get(year)+Integer.parseInt(strs[10])); 73 }else{ 74 map.put(year, Integer.parseInt(strs[10])); 75 } 76 77 } catch (Exception e) { 78 // TODO Auto-generated catch block 79 80 } 81 82 } 83 } 84 //System.out.println(map); 85 86 //记录死亡人数最多的年份 87 int max_year=-1; 88 //记录死亡人数 89 int dead_count=0; 90 //用set无序获取map中的key值,即年份 91 Set<Integer> keyset=map.keySet(); 92 // 93 for(int year:keyset){ 94 //当前年事故死亡最多的年份,记录年和次数 95 if(map.get(year)>dead_count&&map.get(year)<10000){ 96 max_year=year; 97 dead_count=map.get(year); 98 } 99 } 100 101 System.out.println("死亡人数最多的年份:"+(max_year+1901)+" 死亡人数:"+dead_count); 102 } 103 /** 104 * 记录事故次数最多的年份 105 * 输出该年及事故次数 106 */ 107 public static void MaxAccidentsYear(){ 108 //存放年份,该年的事故次数 109 Map<Integer,Integer> map=new HashMap<>(); 110 SimpleDateFormat sdf =new SimpleDateFormat("MM/dd/YYYY"); 111 //循环所有数据 112 for(String data:alldata){ 113 String[] strs=data.split(","); 114 if(strs[0]!=null){ 115 try { 116 Date date=sdf.parse(strs[0]); 117 //获取年份 118 int year=date.getYear(); 119 //判断是否存在记录 120 if(map.containsKey(year)){ 121 //已存在记录,+1 122 map.put(year, map.get(year)+1); 123 }else{ 124 map.put(year, 1); 125 } 126 } catch (Exception e) { 127 // TODO Auto-generated catch block 128 } 129 } 130 } 131 //记录事故次数最多的年份 132 int max_year=0; 133 //该年事故发生次数 134 int acc_count=0; 135 //循环所有数据,获取事故次数最多的年份 136 Set<Integer> keyset=map.keySet(); 137 for(int year:keyset){ 138 if(map.get(year)>acc_count){ 139 max_year=year; 140 acc_count=map.get(year); 141 } 142 } 143 //输出结果 144 System.out.println("事故次数最多的年份"+(max_year+1901)+" 该年事故发生次数:"+acc_count); 145 } 146 /** 147 * FrequencyPeriod() 148 * 各个时间段发生事故的次数 149 */ 150 public static void FrequencyPeriod(){ 151 //key为时间段,value为发生事故次数 152 Map<String,Integer> map=new HashMap<>(); 153 //String数组存放时间段 154 String[] strsTime={"上午(6:00~12:00)","下午(12:00~18:00)","晚上(18:00~24:00)","凌晨(0:00~6:00)"}; 155 //小时:分钟 156 SimpleDateFormat sdf=new SimpleDateFormat("HH:mm"); 157 158 for(String data:alldata){ 159 String[] strs=data.split(","); 160 //判断时间是否记录,未记录则忽略 161 if(strs[1]!=null){ 162 try { 163 Date date=sdf.parse(strs[1]); 164 //取得小时数 165 int hour=date.getHours(); 166 //判断小时数在哪个范围中 167 int index=0; 168 if(hour>=12&&hour<18){ 169 index=1; 170 }else if(hour>=18){ 171 index=2; 172 }else if(hour<6){ 173 index=3; 174 } 175 //记录到map中 176 if(map.containsKey(strsTime[index])){ 177 map.put(strsTime[index], map.get(strsTime[index])+1); 178 }else{ 179 map.put(strsTime[index], 1); 180 } 181 } catch (ParseException e) { 182 } 183 } 184 185 } 186 /* 187 System.out.println("各时间段发生事故次数:"); 188 for(int i=0;i<strsTime.length;i++){ 189 System.out.println(strsTime[i]+" : "+map.get(strsTime[i])); 190 } 191 */ 192 // 记录出事故最多的时间范围 193 String maxTime = null; 194 // 记录出事故最多的次数 195 int maxCount = 0; 196 197 Set<String> keySet = map.keySet(); 198 for (String timeScope : keySet) { 199 if (map.get(timeScope) > maxCount) { 200 // 当前年就是出事故最多的年份,记录下年和次数 201 maxTime = timeScope; 202 maxCount = map.get(timeScope); 203 } 204 } 205 System.out.println("发生事故次数最多的时间段:"); 206 System.out.println(maxTime+" : "+maxCount); 207 } 208 /** 209 * 获取幸村率最高的一条数据的内容 210 * 返回该内容及幸存率 211 */ 212 public static void MaximumSurvival(){ 213 //存放事故信息以及该事故的幸村率 214 Map<String,Float> map=new HashMap<>(); 215 //SimpleDateFormat sdf =new SimpleDateFormat("MM/dd/YYYY"); 216 //事故幸存率=1-死亡率,第十一个是死亡人数,第十个是总人数 217 float survial=0; 218 //循环所有数据 219 for(String data:alldata){ 220 try{ 221 String[] strs=data.split(","); 222 //计算幸存率 223 float m=Float.parseFloat(strs[10]); 224 float n=Float.parseFloat(strs[9]); 225 survial=1-m/n; 226 map.put(data, survial); 227 }catch(Exception e){ 228 229 } 230 } 231 //记录事故次数最多的年份 232 float max_survial=0; 233 //幸存率最高的数据信息 234 String this_data="null"; 235 //循环所有数据,获取事故次数最多的年份 236 Set<String> keyset=map.keySet(); 237 for(String data:keyset){ 238 if(map.get(data)>max_survial){ 239 this_data=data; 240 max_survial=map.get(data); 241 } 242 } 243 System.out.println("幸存率最高的事故是:"+this_data); 244 System.out.println("幸存率为:"+survial); 245 } 246 }
Ⅱ 接下来我们就可以在网页的数据上下手了。
下面先实现一个单网页数据提取的功能。
使用的技术可以有以下几类:
1) 原生代码实现:
a) URL类
2) 使用第三方的URL库
a) HttpClient库
3) 开源爬虫框架
a) Heritrix
b) Nutch
【一】
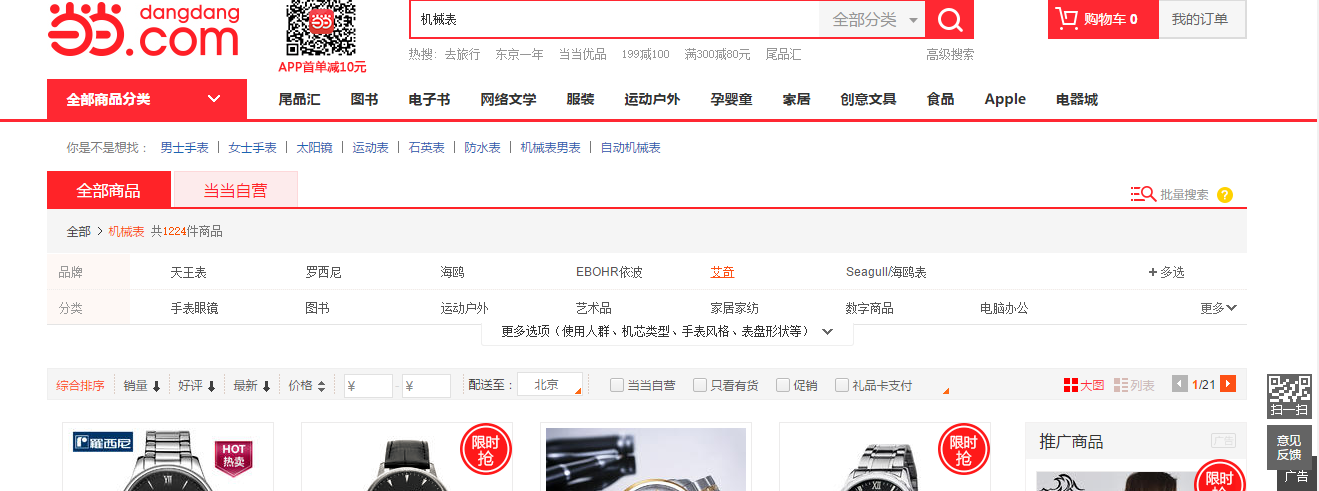
先使用URL类,来将当当网下搜索机械表的内容提取出来。
1 package com.exe1; 2 /** 3 * 读取当当网下机械表的数据,并进行分析 4 * sunwengang 2017-08-13 20:00 5 */ 6 import java.io.*; 7 import java.net.*; 8 9 public class URLDemo { 10 public static void main(String args[]){ 11 //确定爬取的网页地址,此处为当当网搜机械表显示的网页 12 //网址为 http://search.dangdang.com/?key=%BB%FA%D0%B5%B1%ED&act=input 13 String strurl="http://search.dangdang.com/?key=%BB%FA%D0%B5%B1%ED&act=input"; 14 //建立url爬取核心对象 15 try { 16 URL url=new URL(strurl); 17 //通过url建立与网页的连接 18 URLConnection conn=url.openConnection(); 19 //通过链接取得网页返回的数据 20 InputStream is=conn.getInputStream(); 21 22 System.out.println(conn.getContentEncoding()); 23 //一般按行读取网页数据,并进行内容分析 24 //因此用BufferedReader和InputStreamReader把字节流转化为字符流的缓冲流 25 //进行转换时,需要处理编码格式问题 26 BufferedReader br=new BufferedReader(new InputStreamReader(is,"UTF-8")); 27 28 //按行读取并打印 29 String line=null; 30 while((line=br.readLine())!=null){ 31 System.out.println(line); 32 } 33 34 br.close(); 35 } catch (Exception e) { 36 // TODO Auto-generated catch block 37 e.printStackTrace(); 38 } 39 40 } 41 }
结果显示:

【二】
下面尝试将这个网页的源代码保存成为本地的一个文本文件,以便后续做离线分析。
如果想根据条件提取网页中的内容信息,那么就需要使用Java的正则表达式。
正则表达式
Java.util包下提供了Pattern和Matcher这两个类,可以根据我们给定的条件来进行数据的匹配和提取。
通过Pattern类中提供的规则字符或字符串,我们需要自己拼凑出我们的匹配规则。
正则表达式最常用的地方是用来做表单提交的数据格式验证的。
常用的正则表达式规则一般分为两类:
1) 内容匹配
a) \d:是否是数字
b) \w:匹配 字母、数字或下划线
c) .:任意字符
d) [a-z]:字符是否在给定范围内。
2) 数量匹配
a) +:1个或以上
b) *:0个或以上
c) ?:0或1次
d) {n,m}:n-m次
匹配手机电话号码:
规则:1\\d{10}
匹配邮件地址:
规则:\\w+@\\w+.\\w+(\\.\\w+)?
通过Pattern和Matcher的配合,我们可以把一段内容中匹配我们要求的文字提取出来,方便我们来处理。
例如:将一段内容中的电话号码提取出来。
1 public class PatternDemo { 2 3 public static void main(String[] args) { 4 Pattern p = Pattern.compile("1\\d{10}"); 5 6 String content = "<div><div class='jg666'>[转让]<a href='/17610866588' title='手机号码17610866588估价评估_值多少钱_归属地查询_测吉凶_数字含义_求购转让信息' class='lj44'>17610866588</a>由 张云龙 300元转让,联系电话:17610866588</div><div class='jg666'>[转让]<a href='/17777351513' title='手机号码17777351513估价评估_值多少钱_归属地查询_测吉凶_数字含义_求购转让信息' class='lj44'>17777351513</a>由 胡俊宏 888元转让,QQ:762670775,联系电话:17777351513,可以小砍价..</div><div class='jg666'>[求购]<a href='/15019890606' title='手机号码15019890606估价评估_值多少钱_归属地查询_测吉凶_数字含义_求购转让信息' class='lj44'>15019890606</a>由 张宝红 600元求购,联系电话:15026815169</div><div class='jg666'>"; 7 8 Matcher m = p.matcher(content); 9 // System.out.println(p.matcher("sf@sina").matches()); 10 Set<String> set = new HashSet<>(); 11 // 通过Matcher类的group方法和find方法来进行查找和匹配 12 while (m.find()) { 13 String value = m.group(); 14 set.add(value); 15 } 16 System.out.println(set); 17 } 18 }
通过正则表达式完成超连接的连接匹配和提取
对爬取的HTML页面来说,如果想提取连接地址,就必须找到所有超连接的标签和对应的属性。
超连接标签是<a></a>,保存连接的属性是:href。
<a href=”…”>…</a>
规则:
<a .*href=.+</a>
广度优先遍历
需要有一个队列(这里直接使用ArrayList来作为队列)保存所有等待爬取的连接。
还需要一个Set集合记录下所有已经爬取过的连接。
还需要一个深度值,记录当前爬取的网页深度,判断是否满足要求
此时对当当网首页分类里的图书进行深度为2的网页爬取,参照上述对机械表单网页的爬取,利用递归的方式进行数据获取存到E:/dangdang_book/目录下:
1 package com.exe1; 2 /** 3 * 读取当当网下首页图书的数据,并进行分析 4 * 爬取深度为2 5 * 爬去数据存储到E:/dangdang_book/目录下,需自行创建 6 * sunwengang 2017-08-13 20:00 7 */ 8 import java.io.*; 9 import java.net.*; 10 import java.util.*; 11 import java.util.regex.*; 12 13 public class URLDemo { 14 //提取的数据存放到该目录下 15 private static String savepath="E:/dangdang_book/"; 16 //等待爬取的url 17 private static List<String> allwaiturl=new ArrayList<>(); 18 //爬取过的url 19 private static Set<String> alloverurl=new HashSet<>(); 20 //记录所有url的深度进行爬取判断 21 private static Map<String,Integer> allurldepth=new HashMap<>(); 22 //爬取得深度 23 private static int maxdepth=2; 24 25 public static void main(String args[]){ 26 //确定爬取的网页地址,此处为当当网首页上的图书分类进去的网页 27 //网址为 http://book.dangdang.com/ 28 // String strurl="http://search.dangdang.com/?key=%BB%FA%D0%B5%B1%ED&act=input"; 29 String strurl="http://book.dangdang.com/"; 30 31 workurl(strurl,1); 32 33 } 34 public static void workurl(String strurl,int depth){ 35 //判断当前url是否爬取过 36 if(!(alloverurl.contains(strurl)||depth>maxdepth)){ 37 //建立url爬取核心对象 38 try { 39 URL url=new URL(strurl); 40 //通过url建立与网页的连接 41 URLConnection conn=url.openConnection(); 42 //通过链接取得网页返回的数据 43 InputStream is=conn.getInputStream(); 44 45 System.out.println(conn.getContentEncoding()); 46 //一般按行读取网页数据,并进行内容分析 47 //因此用BufferedReader和InputStreamReader把字节流转化为字符流的缓冲流 48 //进行转换时,需要处理编码格式问题 49 BufferedReader br=new BufferedReader(new InputStreamReader(is,"GB2312")); 50 51 //按行读取并打印 52 String line=null; 53 //正则表达式的匹配规则提取该网页的链接 54 Pattern p=Pattern.compile("<a .*href=.+</a>"); 55 //建立一个输出流,用于保存文件,文件名为执行时间,以防重复 56 PrintWriter pw=new PrintWriter(new File(savepath+System.currentTimeMillis()+".txt")); 57 58 while((line=br.readLine())!=null){ 59 //System.out.println(line); 60 //编写正则,匹配超链接地址 61 pw.println(line); 62 Matcher m=p.matcher(line); 63 while(m.find()){ 64 String href=m.group(); 65 //找到超链接地址并截取字符串 66 //有无引号 67 href=href.substring(href.indexOf("href=")); 68 if(href.charAt(5)=='\"'){ 69 href=href.substring(6); 70 }else{ 71 href=href.substring(5); 72 } 73 //截取到引号或者空格或者到">"结束 74 try{ 75 href=href.substring(0,href.indexOf("\"")); 76 }catch(Exception e){ 77 try{ 78 href=href.substring(0,href.indexOf(" ")); 79 }catch(Exception e1){ 80 href=href.substring(0,href.indexOf(">")); 81 } 82 } 83 if(href.startsWith("http:")||href.startsWith("https:")){ 84 //输出该网页存在的链接 85 //System.out.println(href); 86 //将url地址放到队列中 87 allwaiturl.add(href); 88 allurldepth.put(href,depth+1); 89 } 90 91 } 92 93 } 94 pw.close(); 95 br.close(); 96 } catch (Exception e) { 97 // TODO Auto-generated catch block 98 e.printStackTrace(); 99 } 100 //将当前url归列到alloverurl中 101 alloverurl.add(strurl); 102 System.out.println(strurl+"网页爬取完成,已爬取数量:"+alloverurl.size()+",剩余爬取数量:"+allwaiturl.size()); 103 } 104 //用递归的方法继续爬取其他链接 105 String nexturl=allwaiturl.get(0); 106 allwaiturl.remove(0); 107 workurl(nexturl,allurldepth.get(nexturl)); 108 } 109 }
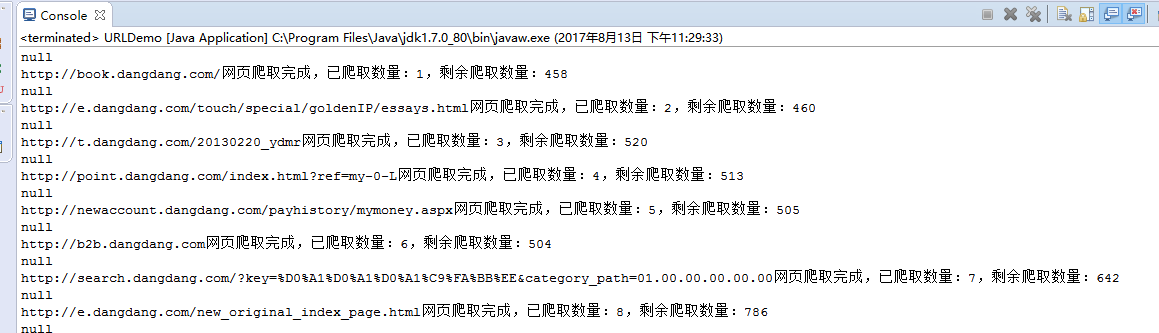
控制台显示:
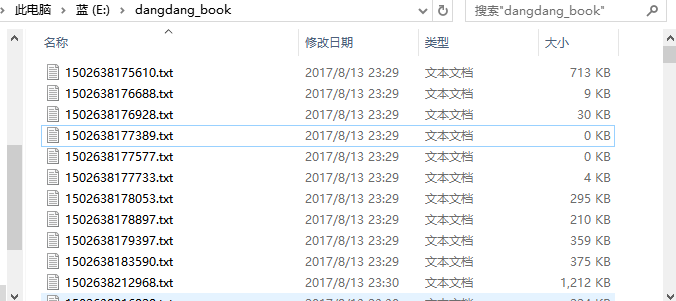
本地目录显示:
但是,仅是深度为2的也运行不短地时间,
如果想提高爬虫性能,那么我们就需要使用多线程来处理,例如:准备好5个线程来同时进行爬虫操作。
这些线程需要标注出当前状态,是在等待,还是在爬取。
如果是等待状态,那么就需要取得集合中的一个连接,来完成爬虫操作。
如果是爬取状态,则在爬完以后,需要变为等待状态。
多线程中如果想设置等待状态,有一个方法可以实现:wait(),如果想从等待状态唤醒,则可以使用notify()。
因此在多个线程中间我们需要一个对象来帮助我们进行线程之间的通信,以便唤醒其它线程。
多线程同时处理时,容易出现线程不安全的问题,导致数据出现错误。
为了保证线程的安全,就需要使用同步关键字,来对取得连接和放入连接操作加锁。
多线程爬虫实现
需要先自定义一个线程的操作类,在这个操作类中判断不同的状态,并且根据状态来决定是进行wait()等待,还是取得一个新的url进行处理。
1 package com.exe1; 2 /** 3 * 读取当当网下首页图书的数据,并进行分析 4 * 爬取深度为2 5 * 爬去数据存储到E:/dangdang_book/目录下,需自行创建 6 * 孙文刚 2017-08-13 20:00 7 */ 8 import java.io.*; 9 import java.net.*; 10 import java.util.*; 11 import java.util.regex.*; 12 13 public class URLDemo { 14 //提取的数据存放到该目录下 15 private static String savepath="E:/dangdang_book/"; 16 //等待爬取的url 17 private static List<String> allwaiturl=new ArrayList<>(); 18 //爬取过的url 19 private static Set<String> alloverurl=new HashSet<>(); 20 //记录所有url的深度进行爬取判断 21 private static Map<String,Integer> allurldepth=new HashMap<>(); 22 //爬取得深度 23 private static int maxdepth=2; 24 //生命对象,帮助进行线程的等待操作 25 private static Object obj=new Object(); 26 //记录总线程数5条 27 private static int MAX_THREAD=5; 28 //记录空闲的线程数 29 private static int count=0; 30 31 public static void main(String args[]){ 32 //确定爬取的网页地址,此处为当当网首页上的图书分类进去的网页 33 //网址为 http://book.dangdang.com/ 34 // String strurl="http://search.dangdang.com/?key=%BB%FA%D0%B5%B1%ED&act=input"; 35 String strurl="http://book.dangdang.com/"; 36 37 //workurl(strurl,1); 38 addurl(strurl,0); 39 for(int i=0;i<MAX_THREAD;i++){ 40 new URLDemo().new MyThread().start(); 41 } 42 } 43 /** 44 * 网页数据爬取 45 * @param strurl 46 * @param depth 47 */ 48 public static void workurl(String strurl,int depth){ 49 //判断当前url是否爬取过 50 if(!(alloverurl.contains(strurl)||depth>maxdepth)){ 51 //检测线程是否执行 52 System.out.println("当前执行:"+Thread.currentThread().getName()+" 爬取线程处理爬取:"+strurl); 53 //建立url爬取核心对象 54 try { 55 URL url=new URL(strurl); 56 //通过url建立与网页的连接 57 URLConnection conn=url.openConnection(); 58 //通过链接取得网页返回的数据 59 InputStream is=conn.getInputStream(); 60 61 //提取text类型的数据 62 if(conn.getContentType().startsWith("text")){ 63 64 } 65 System.out.println(conn.getContentEncoding()); 66 //一般按行读取网页数据,并进行内容分析 67 //因此用BufferedReader和InputStreamReader把字节流转化为字符流的缓冲流 68 //进行转换时,需要处理编码格式问题 69 BufferedReader br=new BufferedReader(new InputStreamReader(is,"GB2312")); 70 71 //按行读取并打印 72 String line=null; 73 //正则表达式的匹配规则提取该网页的链接 74 Pattern p=Pattern.compile("<a .*href=.+</a>"); 75 //建立一个输出流,用于保存文件,文件名为执行时间,以防重复 76 PrintWriter pw=new PrintWriter(new File(savepath+System.currentTimeMillis()+".txt")); 77 78 while((line=br.readLine())!=null){ 79 //System.out.println(line); 80 //编写正则,匹配超链接地址 81 pw.println(line); 82 Matcher m=p.matcher(line); 83 while(m.find()){ 84 String href=m.group(); 85 //找到超链接地址并截取字符串 86 //有无引号 87 href=href.substring(href.indexOf("href=")); 88 if(href.charAt(5)=='\"'){ 89 href=href.substring(6); 90 }else{ 91 href=href.substring(5); 92 } 93 //截取到引号或者空格或者到">"结束 94 try{ 95 href=href.substring(0,href.indexOf("\"")); 96 }catch(Exception e){ 97 try{ 98 href=href.substring(0,href.indexOf(" ")); 99 }catch(Exception e1){ 100 href=href.substring(0,href.indexOf(">")); 101 } 102 } 103 if(href.startsWith("http:")||href.startsWith("https:")){ 104 /* 105 //输出该网页存在的链接 106 //System.out.println(href); 107 //将url地址放到队列中 108 allwaiturl.add(href); 109 allurldepth.put(href,depth+1); 110 */ 111 //调用addurl方法 112 addurl(href,depth); 113 } 114 115 } 116 117 } 118 pw.close(); 119 br.close(); 120 } catch (Exception e) { 121 // TODO Auto-generated catch block 122 //e.printStackTrace(); 123 } 124 //将当前url归列到alloverurl中 125 alloverurl.add(strurl); 126 System.out.println(strurl+"网页爬取完成,已爬取数量:"+alloverurl.size()+",剩余爬取数量:"+allwaiturl.size()); 127 } 128 /* 129 //用递归的方法继续爬取其他链接 130 String nexturl=allwaiturl.get(0); 131 allwaiturl.remove(0); 132 workurl(nexturl,allurldepth.get(nexturl)); 133 */ 134 if(allwaiturl.size()>0){ 135 synchronized(obj){ 136 obj.notify(); 137 } 138 }else{ 139 System.out.println("爬取结束......."); 140 } 141 142 } 143 /** 144 * 将获取的url放入等待队列中,同时判断是否已经放过 145 * @param href 146 * @param depth 147 */ 148 public static synchronized void addurl(String href,int depth){ 149 //将url放到队列中 150 allwaiturl.add(href); 151 //判断url是否放过 152 if(!allurldepth.containsKey(href)){ 153 allurldepth.put(href, depth+1); 154 } 155 } 156 /** 157 * 移除爬取完成的url,获取下一个未爬取得url 158 * @return 159 */ 160 public static synchronized String geturl(){ 161 String nexturl=allwaiturl.get(0); 162 allwaiturl.remove(0); 163 return nexturl; 164 } 165 /** 166 * 线程分配任务 167 */ 168 public class MyThread extends Thread{ 169 @Override 170 public void run(){ 171 //设定一个死循环,让线程一直存在 172 while(true){ 173 //判断是否新链接,有则获取 174 if(allwaiturl.size()>0){ 175 //获取url进行处理 176 String url=geturl(); 177 //调用workurl方法爬取 178 workurl(url,allurldepth.get(url)); 179 }else{ 180 System.out.println("当前线程准备就绪,等待连接爬取:"+this.getName()); 181 count++; 182 //建立一个对象,让线程进入等待状态,即wait() 183 synchronized(obj){ 184 try{ 185 obj.wait(); 186 }catch(Exception e){ 187 188 } 189 } 190 count--; 191 } 192 } 193 } 194 195 } 196 }
控制台显示:

本地目录显示:
总结:
对于网页数据爬取,用到了线程,类集处理,继承,正则表达式等各方面的知识,从一个网页以深度为主,广度为基本进行爬取,获取每一个网页的源代码,并写入到一个本地的目录下。
1、给出一个网页链接,创建一个本地目录;
2、用URL类本地连接,用字符流进行读取,并写入到本地;
3、利用正则表达式在按行读取时获取该网页所存在的所有链接,以便进行深度+1的数据收集;
4、利用递归的方法,借助容器list,Set,Map来对链接进行爬取和未爬取得划分;
5、每次爬取一个网页时,所获得的所有链接在当前基础上深度+1,并且从未爬取队列中移除,加入到已爬取队列中;
6、为提升性能,在进行递归的时候,可以利用线程,复写Thread的run()方法,用多线程进行网页数据爬取;
7、直到爬取得网页深度达到你期望的深度时,爬取结束,此时可以查看本地目录生成的文件;
8、后续对本地生成的文件进行数据分析,即可获取你想要的信息。
借此,我们就可以对这些数据进行归约,分析,处理,来获取我们想要的信息。
这也是大数据数据收集的一个基础。

发表评论 取消回复