Java 常用List集合使用场景分析
过年前的最后一篇,本章通过介绍ArrayList,LinkedList,Vector,CopyOnWriteArrayList 底层实现原理和四个集合的区别。让你清楚明白,为什么工作中会常用ArrayList和CopyOnWriteArrayList?了解底层实现原理,我们可以学习到很多代码设计的思路,开阔自己的思维。本章通俗易懂,还在等什么,快来学习吧!
知识图解:
技术:ArrayList,LinkedList,Vector,CopyOnWriteArrayList
说明:本章基于jdk1.8,github上有ArrayList,LinkedList的简单源码代码
源码:https://github.com/ITDragonBlog/daydayup/tree/master/Java/collection-stu
知识预览
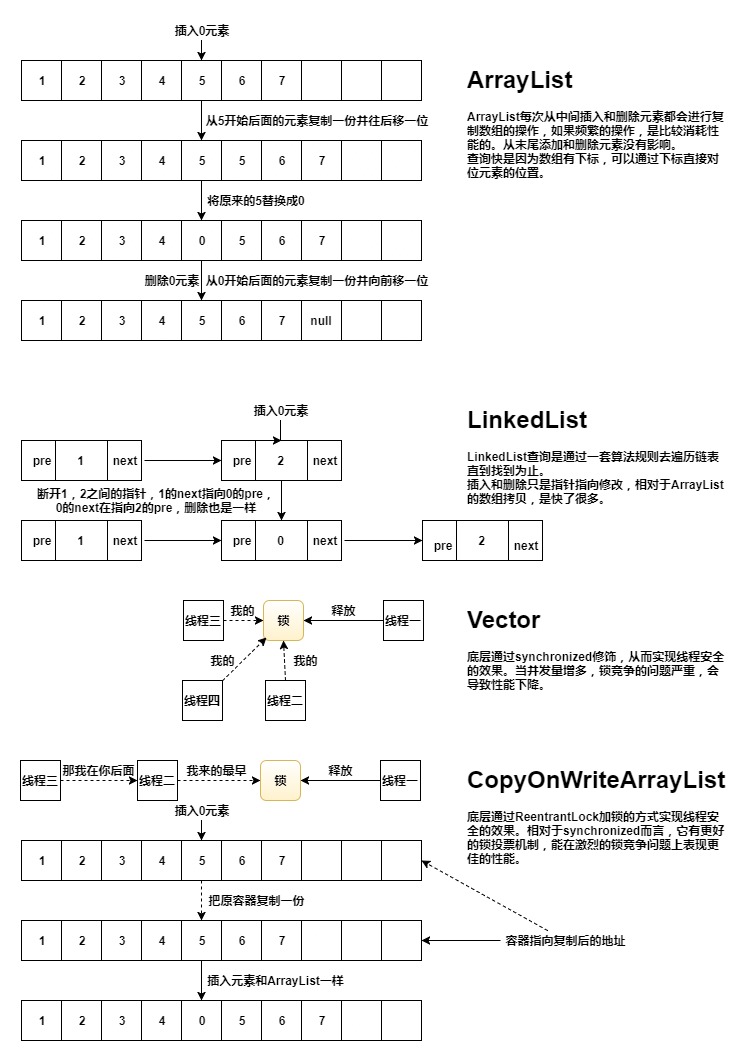
ArrayList : 基于数组实现的非线程安全的集合。查询元素快,插入,删除中间元素慢。
LinkedList : 基于链表实现的非线程安全的集合。查询元素慢,插入,删除中间元素快。
Vector : 基于数组实现的线程安全的集合。线程同步(方法被synchronized修饰),性能比ArrayList差。
CopyOnWriteArrayList : 基于数组实现的线程安全的写时复制集合。线程安全(ReentrantLock加锁),性能比Vector高,适合读多写少的场景。
ArrayList 和 LinkedList 读写快慢的本质
ArrayList : 查询数据快,是因为数组可以通过下标直接找到元素。 写数据慢有两个原因:一是数组复制过程需要时间,二是扩容需要实例化新数组也需要时间。
LinkedList : 查询数据慢,是因为链表需要遍历每个元素直到找到为止。 写数据快有一个原因:除了实例化对象需要时间外,只需要修改指针即可完成添加和删除元素。
本章会通过源码分析,验证上面的说法。
注:这里的块和慢是相对的。并不是LinkedList的插入和删除就一定比ArrayList快。明白其快慢的本质:ArrayList快在定位,慢在数组复制。LinkedList慢在定位,快在指针修改。
ArrayList
ArrayList 是基于动态数组实现的非线程安全的集合。当底层数组满的情况下还在继续添加的元素时,ArrayList则会执行扩容机制扩大其数组长度。ArrayList查询速度非常快,使得它在实际开发中被广泛使用。美中不足的是插入和删除元素较慢,同时它并不是线程安全的。
我们可以从源码中找到答案
// 查询元素
public E get(int index) {
rangeCheck(index); // 检查是否越界
return elementData(index);
}
// 顺序添加元素
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 扩容机制
elementData[size++] = e;
return true;
}
// 从数组中间添加元素
public void add(int index, E element) {
rangeCheckForAdd(index); // 数组下标越界检查
ensureCapacityInternal(size + 1); // 扩容机制
System.arraycopy(elementData, index, elementData, index + 1, size - index); // 复制数组
elementData[index] = element; // 替换元素
size++;
}
// 从数组中删除元素
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
}
从源码中可以得知,
ArrayList在执行查询操作时:
第一步:先判断下标是否越界。
第二步:然后在直接通过下标从数组中返回元素。
ArrayList在执行顺序添加操作时:
第一步:通过扩容机制判断原数组是否还有空间,若没有则重新实例化一个空间更大的新数组,把旧数组的数据拷贝到新数组中。
第二步:在新数组的最后一位元素添加值。
ArrayList在执行中间插入操作时:
第一步:先判断下标是否越界。
第二步:扩容。
第三步:若插入的下标为i,则通过复制数组的方式将i后面的所有元素,往后移一位。
第四步:新数据替换下标为i的旧元素。
删除也是一样:只是数组往前移了一位,最后一个元素设置为null,等待JVM垃圾回收。
从上面的源码分析,我们可以得到一个结论和一个疑问。
结论是:ArrayList快在下标定位,慢在数组复制。
疑问是:能否将每次扩容的长度设置大点,减少扩容的次数,从而提高效率?其实每次扩容的长度大小是很有讲究的。若扩容的长度太大,会造成大量的闲置空间;若扩容的长度太小,会造成频发的扩容(数组复制),效率更低。
LinkedList
LinkedList 是基于双向链表实现的非线程安全的集合,它是一个链表结构,不能像数组一样随机访问,必须是每个元素依次遍历直到找到元素为止。其结构的特殊性导致它查询数据慢。
我们可以从源码中找到答案
// 查询元素
public E get(int index) {
checkElementIndex(index); // 检查是否越界
return node(index).item;
}
Node<E> node(int index) {
if (index < (size >> 1)) { // 类似二分法
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
// 插入元素
public void add(int index, E element) {
checkPositionIndex(index); // 检查是否越界
if (index == size) // 在链表末尾添加
linkLast(element);
else // 在链表中间添加
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
从源码中可以得知,
LinkedList在执行查询操作时:
第一步:先判断元素是靠近头部,还是靠近尾部。
第二步:若靠近头部,则从头部开始依次查询判断。和ArrayList的elementData(index)相比当然是慢了很多。
LinkedList在插入元素的思路:
第一步:判断插入元素的位置是链表的尾部,还是中间。
第二步:若在链表尾部添加元素,直接将尾节点的下一个指针指向新增节点。
第三步:若在链表中间添加元素,先判断插入的位置是否为首节点,是则将首节点的上一个指针指向新增节点。否则先获取当前节点的上一个节点(简称A),并将A节点的下一个指针指向新增节点,然后新增节点的下一个指针指向当前节点。
Vector
Vector 的数据结构和使用方法与ArrayList差不多。最大的不同就是Vector是线程安全的。从下面的源码可以看出,几乎所有的对数据操作的方法都被synchronized关键字修饰。synchronized是线程同步的,当一个线程已经获得Vector对象的锁时,其他线程必须等待直到该锁被释放。从这里就可以得知Vector的性能要比ArrayList低。
若想要一个高性能,又是线程安全的ArrayList,可以使用Collections.synchronizedList(list);方法或者使用CopyOnWriteArrayList集合
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
public synchronized boolean removeElement(Object obj) {
modCount++;
int i = indexOf(obj);
if (i >= 0) {
removeElementAt(i);
return true;
}
return false;
}
CopyOnWriteArrayList
在这里我们先简单了解一下CopyOnWrite容器。它是一个写时复制的容器。当我们往一个容器添加元素的时候,不是直接往当前容器添加,而是先将当前容器进行copy一份,复制出一个新的容器,然后对新容器里面操作元素,最后将原容器的引用指向新的容器。所以CopyOnWrite容器是一种读写分离的思想,读和写不同的容器。
应用场景:适合高并发的读操作(读多写少)。若写的操作非常多,会频繁复制容器,从而影响性能。
CopyOnWriteArrayList 写时复制的集合,在执行写操作(如:add,set,remove等)时,都会将原数组拷贝一份,然后在新数组上做修改操作。最后集合的引用指向新数组。
CopyOnWriteArrayList 和Vector都是线程安全的,不同的是:前者使用ReentrantLock类,后者使用synchronized关键字。ReentrantLock提供了更多的锁投票机制,在锁竞争的情况下能表现更佳的性能。就是它让JVM能更快的调度线程,才有更多的时间去执行线程。这就是为什么CopyOnWriteArrayList的性能在大并发量的情况下优于Vector的原因。
private E get(Object[] a, int index) {
return (E) a[index];
}
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
private boolean remove(Object o, Object[] snapshot, int index) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] current = getArray();
int len = current.length;
......
Object[] newElements = new Object[len - 1];
System.arraycopy(current, 0, newElements, 0, index);
System.arraycopy(current, index + 1, newElements, index, len - index - 1);
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
总结
看到这里,如果面试官问你ArrayList和LinkedList有什么区别时
如果你回答:ArrayList查询快,写数据慢;LinkedList查询慢,写数据快。面试官只能算你勉强合格。
如果你回答:ArrayList查询快是因为底层是由数组实现,通过下标定位数据快。写数据慢是因为复制数组耗时。LinkedList底层是双向链表,查询数据依次遍历慢。写数据只需修改指针引用。
如果你继续回答:ArrayList和LinkedList都不是线程安全的,小并发量的情况下可以使用Vector,若并发量很多,且读多写少可以考虑使用CopyOnWriteArrayList。
因为CopyOnWriteArrayList底层使用ReentrantLock锁,比使用synchronized关键字的Vector能更好的处理锁竞争的问题。
面试官会认为你是一个基础扎实,内功深厚的人才!!!
到这里Java 常用List集合使用场景分析就结束了。过年前的最后一篇博客,有点浮躁,可能身在职场,心在老家!最后祝大家新年快乐!!!狗年吉祥!!!大富大贵!!!可能都没人看博客了 ⊙﹏⊙‖∣ 哈哈哈哈(ಡωಡ)hiahiahia

发表评论 取消回复