java应用程序的启动在在/hotspot/src/share/tools/launcher/java.c的main()函数中,而在虚拟机初始化过程中,将创建并启动Java的Main线程。最后将调用JNIEnv的CallStaticVoidMethod()来执行main方法。
CallStaticVoidMethod()对应的jni函数为jni_CallStaticVoidMethod,定义在/hotspot/src/share/vm/prims/jni.cpp中,而jni_CallStaticVoidMethod()又调用了jni_invoke_static(),jni_invoke_static()通过JavaCalls的call()发起对Java方法的调用
所有来自虚拟机对Java函数的调用最终都将由JavaCalls模块来完成,JavaCalls将通过call_helper()来执行Java方法并返回调用结果,并最终调用StubRoutines::call_stub()来执行Java方法:

1 // do call 2 { JavaCallWrapper link(method, receiver, result, CHECK); 3 { HandleMark hm(thread); // HandleMark used by HandleMarkCleaner 4 5 StubRoutines::call_stub()( 6 (address)&link, 7 // (intptr_t*)&(result->_value), // see NOTE above (compiler problem) 8 result_val_address, // see NOTE above (compiler problem) 9 result_type, 10 method(), 11 entry_point, 12 args->parameters(), 13 args->size_of_parameters(), 14 CHECK 15 ); 16 17 result = link.result(); // circumvent MS C++ 5.0 compiler bug (result is clobbered across call) 18 // Preserve oop return value across possible gc points 19 if (oop_result_flag) { 20 thread->set_vm_result((oop) result->get_jobject()); 21 } 22 } 23 }
call_stub()定义在/hotspot/src/share/vm/runtime/stubRoutines.h中,实际上返回的就是CallStub函数指针_call_stub_entry,该指针指向call_stub的汇编实现的目标代码指令地址,即call_stub的例程入口。
// Calls to Java typedef void (*CallStub)( address link, intptr_t* result, BasicType result_type, methodOopDesc* method, address entry_point, intptr_t* parameters, int size_of_parameters, TRAPS ); static CallStub call_stub() { return CAST_TO_FN_PTR(CallStub, _call_stub_entry); }
在分析call_stub的汇编代码之前,先了解下x86寄存器和栈帧以及函数调用的相关知识。
x86-64的所有寄存器都是与机器字长(数据总线位宽)相同,即64位的,x86-64将x86的8个32位通用寄存器扩展为64位(eax、ebx、ecx、edx、eci、edi、ebp、esp),并且增加了8个新的64位寄存器(r8-r15),在命名方式上,也从”exx”变为”rxx”,但仍保留”exx”进行32位操作,下表描述了各寄存器的命名和作用
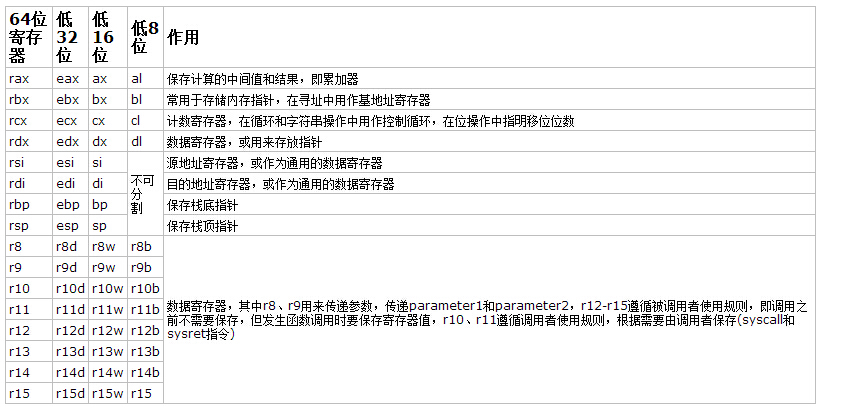
此外,还有16个128位的XMM寄存器,分别为xmm0-15,x84-64的寄存器遵循调用约定(Calling Conventions):
https://msdn.microsoft.com/en-US/library/zthk2dkh(v=vs.80).aspx
1.参数传递:
(1).前4个参数的int类型分别通过rcx、rdx、r8、r9传递,多余的在栈空间上传递(从右向左依次入栈),寄存器所有的参数都是向右对齐的(低位对齐)
(2).浮点数类型的参数通过xmm0-xmm3传递,注意不同类型的参数占用的寄存器序号是根据参数的序号来决定的,比如add(int,double,float,int)就分别保存在rcx、xmm1、xmm2、r9寄存器中
(3).8/16/32/64类型的结构体或共用体和_m64类型将使用rcx、rdx、r8、r9直接传递,而其他类型将会通过指针引用的方式在这4个寄存器中传递
(4).被调用函数当需要时要把寄存器中的参数移动到栈空间中(shadow space)
2.返回值传递
(1).对于可以填充为64位的返回值(包括_m64)将使用rax进行传递
(2).对于_m128(i/d)以及浮点数类型将使用xmm0传递
(3).对于64位以上的返回值,将由调用函数在栈上为其分配空间,并将其指针保存在rcx中作为”第一个参数”,而传入参数将依次右移,最后函数调用完后,由rax返回该空间的指针
(4).用户定义的返回值类型长度必须是1、2、4、8、16、32、64
3.调用者/被调用者保存寄存器
调用者保存寄存器:rax、rcx、rdx、r8-r11都认为是易失型寄存器(volatile),这些寄存器随时可能被用到,这些寄存器将由调用者自行维护,当调用其他函数时,被调用函数对这些寄存器的操作并不会影响调用函数(即这些寄存器的作用范围仅限于当前函数)。
被调用者保存寄存器:rbx、rbp、rdi、rsi、r12-r15、xmm6-xmm15都是非易失型寄存器(non-volatile),调用其他函数时,这些寄存器的值可能在调用返回时还需要用,那么被调用函数就必须将这些寄存器的值保存起来,当要返回时,恢复这些寄存器的值(即这些寄存器的作用范围是跨函数调用的)。
以如下程序为例,分析函数调用的栈帧布局:
1 double func(int param_i1, float param_f1, double param_d1, int param_i2, double param_d2) 2 3 { 4 int local_i1, local_i2; 5 float local_f1; 6 double local_d1; 7 double local_d2 = 3.0; 8 local_i1 = param_i1; 9 local_i2 = param_i2; 10 local_f1 = param_f1; 11 local_d1 = param_d1; 12 return local_d1 + local_f1 * (local_i2 - local_i1) - param_d2 + local_d2; 13 } 14 15 int main() 16 17 { 18 double res; 19 res = func(1, 1.0, 2.0, 3, 3.0); 20 return 0; 21 }
main函数调用func之前的汇编代码如下:
main: pushq %rbp //保存rbp .seh_pushreg %rbp movq %rsp, %rbp //更新栈基址 .seh_setframe %rbp, 0 subq $80, %rsp .seh_stackalloc 80 //main栈需要80字节的栈空间 .seh_endprologue call __main movabsq $4611686018427387904, %rdx //0x4000000000000000,即浮点数2.0 movabsq $4613937818241073152, %rax //0x3000000000000000,即浮点数3.0 movq %rax, 32(%rsp) //第5个参数3.0,即param_d2保存在栈空间上 movl $3, %r9d //第4个参数3,即param_i2保存在r9d中(r9的低32位) movq %rdx, -24(%rbp) movsd -24(%rbp), %xmm2 //第3个参数2.0,即param_d1保存在xmm2中 movss .LC2(%rip), %xmm1 //第2个参数1.0(0x3f800000),保存在xmm1中 movl $1, %ecx //第1个参数1,保存在ecx中(rcx的低32位) call func
func函数返回后,main函数将从xmm0中取出返回结果
call func movq %xmm0, %rax //保存结果 movq %rax, -8(%rbp) movl $0, %eax //清空eax,回收main栈,恢复栈顶地址 addq $80, %rsp popq %rbp ret
func函数的栈和操作数准备如下:
func: pushq %rbp //保存rbp(main函数栈的基址) .seh_pushreg %rbp movq %rsp, %rbp //将main栈的栈顶指针作为被调用函数的栈基址 .seh_setframe %rbp, 0 subq $32, %rsp //func栈需要32字节的栈空间 .seh_stackalloc 32 .seh_endprologue movl %ecx, 16(%rbp) //将4个参数移动到栈底偏移16-40的空间(main栈的shadow space) movss %xmm1, 24(%rbp) movsd %xmm2, 32(%rbp) movl %r9d, 40(%rbp) movabsq $4613937818241073152, %rax //本地变量local_d2,即浮点数3.0 movq %rax, -8(%rbp) //5个局部变量 movl 16(%rbp), %eax movl %eax, -12(%rbp) movl 40(%rbp), %eax movl %eax, -16(%rbp) movl 24(%rbp), %eax movl %eax, -20(%rbp) movq 32(%rbp), %rax movq %rax, -32(%rbp)
随后的func的运算过程如下:
movl -16(%rbp), %eax //local_i2 - local_i1 subl -12(%rbp), %eax pxor %xmm0, %xmm0 //准备xmm0寄存器,按位异或,xmm0清零 cvtsi2ss %eax, %xmm0 mulss -20(%rbp), %xmm0 //local_f1 * (local_i2 - local_i1) cvtss2sd %xmm0, %xmm0 addsd -32(%rbp), %xmm0 //local_d1 + local_f1 * (local_i2 - local_i1) subsd 48(%rbp), %xmm0 //local_d1 + local_f1 * (local_i2 - local_i1) - param_d2 addsd -8(%rbp), %xmm0 //local_d1 + local_f1 * (local_i2 - local_i1) - param_d2 + local_d2 addq $32, %rsp //回收func栈,恢复栈顶地址 popq %rbp ret
根据以上代码分析,大概得出该程序调用栈结构:
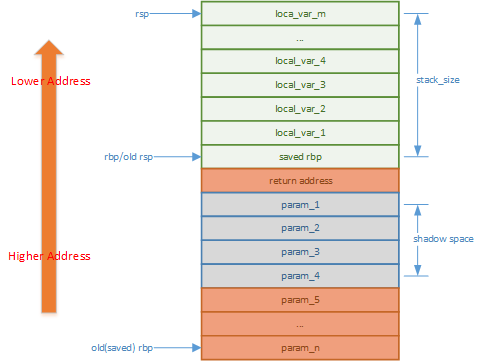
这里没有考虑func函数再次调用其他函数而准备操作数的栈内容的情况,但结合main函数栈,大致可以得出栈的通用结构如下:
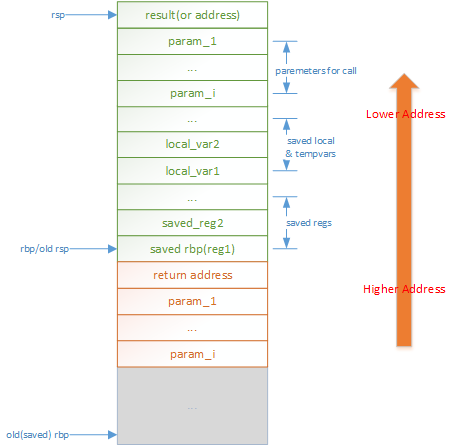
call_stub由generate_call_stub()解释成汇编代码,有兴趣的可以继续阅读call_stub的汇编代码进行分析。
下面对call_stub的汇编部分进行分析:
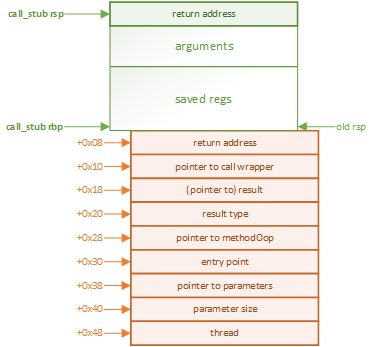
先来看下call_stub的调用栈结构:(注:本文实验是在windows_64位平台上实现的)
// Call stubs are used to call Java from C // return_from_Java 是紧跟在call *%eax后面的那条指令的地址 // [ return_from_Java ] <--- rsp // -28 [ arguments ] <-- rbp - 0xe8 // -26 [ saved xmm15 ] <-- rbp - 0xd8 // -24 [ saved xmm14 ] <-- rbp - 0xc8 // -22 [ saved xmm13 ] <-- rbp - 0xb8 // -20 [ saved xmm12 ] <-- rbp - 0xa8 // -18 [ saved xmm11 ] <-- rbp - 0x98 // -16 [ saved xmm10 ] <-- rbp - 0x88 // -14 [ saved xmm9 ] <-- rbp - 0x78 // -12 [ saved xmm8 ] <-- rbp - 0x68 // -10 [ saved xmm7 ] <-- rbp - 0x58 // -9 [ saved xmm6 ] <-- rbp - 0x48 // -7 [ saved r15 ] <-- rbp - 0x38 // -6 [ saved r14 ] <-- rbp - 0x30 // -5 [ saved r13 ] <-- rbp - 0x28 // -4 [ saved r12 ] <-- rbp - 0x20 // -3 [ saved rdi ] <-- rbp - 0x18 // -2 [ saved rsi ] <-- rbp - 0x10 // -1 [ saved rbx ] <-- rbp - 0x8 // 0 [ saved rbp ] <--- rbp, // 1 [ return address ] <--- rbp + 0x08 // 2 [ ptr. to call wrapper ] <--- rbp + 0x10 // 3 [ result ] <--- rbp + 0x18 // 4 [ result_type ] <--- rbp + 0x20 // 5 [ method ] <--- rbp + 0x28 // 6 [ entry_point ] <--- rbp + 0x30 // 7 [ parameters ] <--- rbp + 0x38 // 8 [ parameter_size ] <--- rbp + 0x40 // 9 [ thread ] <--- rbp + 0x48
1.根据函数调用栈的结构:
在被调函数栈帧的栈底 %rbp + 8(栈地址向下增长,堆地址向上增长,栈底的正偏移值指向调用函数栈帧内容)保存着被调函数的传入参数,这里即:
JavaCallWrapper指针、返回结果指针、返回结果类型、被调用方法的methodOop、被调用方法的解释代码的入口地址、参数地址、参数个数。
StubRoutines::call_stub [0x0000000002400567, 0x00000000024006cb[ (356 bytes) //保存bp 0x0000000002400567: push %rbp //更新栈顶地址 0x0000000002400568: mov %rsp,%rbp //call_stub需要的栈空间大小为0xd8 0x000000000240056b: sub $0xd8,%rsp
2.rcx、rdx、r8d、r9d分别保存着传入call_stub的前4个参数,现在需要将其复制到栈上的shadow space中
//分别使用rcx、rdx、r8、r9来保存第1、2、3、4个参数,多出来的其他参数用栈空间来传递 //使用xmm0-4来传递第1-4个浮点数参数 //这里将参数复制到栈空间,这样call_stub的所有参数就在rbp + 0x10 ~ 0x48栈空间上 0x0000000002400572: mov %r9,0x28(%rbp) 0x0000000002400576: mov %r8d,0x20(%rbp) 0x000000000240057a: mov %rdx,0x18(%rbp) 0x000000000240057e: mov %rcx,0x10(%rbp)
3.将被调用者保存寄存器的值压入call_stub栈中:
;; save registers: //依次保存rbx、rsi、rdi这三个被调用者保存的寄存器,随后保存r12-r15、XMM寄存器组xmm6-xmm15 0x0000000002400582: mov %rbx,-0x8(%rbp) 0x0000000002400586: mov %r12,-0x20(%rbp) 0x000000000240058a: mov %r13,-0x28(%rbp) 0x000000000240058e: mov %r14,-0x30(%rbp) 0x0000000002400592: mov %r15,-0x38(%rbp) 0x0000000002400596: vmovdqu %xmm6,-0x48(%rbp) 0x000000000240059b: vmovdqu %xmm7,-0x58(%rbp) 0x00000000024005a0: vmovdqu %xmm8,-0x68(%rbp) 0x00000000024005a5: vmovdqu %xmm9,-0x78(%rbp) 0x00000000024005aa: vmovdqu %xmm10,-0x88(%rbp) 0x00000000024005b2: vmovdqu %xmm11,-0x98(%rbp) 0x00000000024005ba: vmovdqu %xmm12,-0xa8(%rbp) 0x00000000024005c2: vmovdqu %xmm13,-0xb8(%rbp) 0x00000000024005ca: vmovdqu %xmm14,-0xc8(%rbp) 0x00000000024005d2: vmovdqu %xmm15,-0xd8(%rbp) 0x00000000024005da: mov %rsi,-0x10(%rbp) 0x00000000024005de: mov %rdi,-0x18(%rbp) //栈底指针的0x48偏移保存着thread对象,0x6d01a2c3(%rip)为异常处理入口 0x00000000024005e2: mov 0x48(%rbp),%r15 0x00000000024005e6: mov 0x6d01a2c3(%rip),%r12 # 0x000000006f41a8b0
4.call_stub的参数保存着Java方法的参数,现在就需要将参数压入call_stub栈中
/栈底指针的0x40偏移保存着参数的个数 0x00000000024005ed: mov 0x40(%rbp),%r9d //若参数个数为0,则直接跳转0x000000000240060d准备调用Java方法 0x00000000024005f1: test %r9d,%r9d 0x00000000024005f4: je 0x000000000240060d //若参数个数不为0,则遍历参数,将所有参数压入本地栈 //其中栈底指针的0x38偏移保存着参数的地址,edx将用作循环的迭代器 0x00000000024005fa: mov 0x38(%rbp),%r8 0x00000000024005fe: mov %r9d,%edx ;; loop: //从第一个参数开始,将Java方法的参数压人本地栈 /* * i = parameter_size; //确保不等于0 * do{ * push(parameter[i]); * i--; * }while(i!=0); */ 0x0000000002400601: mov (%r8),%rax 0x0000000002400604: add $0x8,%r8 0x0000000002400608: dec %edx 0x000000000240060a: push %rax 0x000000000240060b: jne 0x0000000002400601
5.调用Java方法的解释代码
;; prepare entry: //栈底指针的0x28和0x30偏移分别保存着被调用Java方法的methodOop指针和解释代码的入口地址 0x000000000240060d: mov 0x28(%rbp),%rbx 0x0000000002400611: mov 0x30(%rbp),%rdx 0x0000000002400615: mov %rsp,%r13 //保存栈顶指针 ;; jump to run Java method: 0x0000000002400618: callq *%rdx
6.准备保存返回结果,这里需要先根据不同的返回类型取出返回结果,然后保存到返回结果指针所指向的位置
;; prepare to save result: //栈底指针的0x18和0x20偏移分别保存着返回结果的指针和结果类型 0x000000000240061a: mov 0x18(%rbp),%rcx 0x000000000240061e: mov 0x20(%rbp),%edx ;; handle result accord to different result_type: 0x0000000002400621: cmp $0xc,%edx 0x0000000002400624: je 0x00000000024006b7 0x000000000240062a: cmp $0xb,%edx 0x000000000240062d: je 0x00000000024006b7 0x0000000002400633: cmp $0x6,%edx 0x0000000002400636: je 0x00000000024006bc 0x000000000240063c: cmp $0x7,%edx 0x000000000240063f: je 0x00000000024006c2 ;; save result for the other result_type: 0x0000000002400645: mov %eax,(%rcx)
下面分别为返回结果类型为long、float、double的情况
;; long 类型返回结果保存: 0x00000000024006b7: mov %rax,(%rcx) 0x00000000024006ba: jmp 0x0000000002400647 ;; float 类型返回结果保存: 0x00000000024006bc: vmovss %xmm0,(%rcx) 0x00000000024006c0: jmp 0x0000000002400647 ;; double 类型返回结果保存: 0x00000000024006c2: vmovsd %xmm0,(%rcx) 0x00000000024006c6: jmpq 0x0000000002400647
7.被调用者保存寄存器的恢复,以及栈指针的复位
;; restore registers: 0x0000000002400647: lea -0xd8(%rbp),%rsp 0x000000000240064e: vmovdqu -0xd8(%rbp),%xmm15 0x0000000002400656: vmovdqu -0xc8(%rbp),%xmm14 0x000000000240065e: vmovdqu -0xb8(%rbp),%xmm13 0x0000000002400666: vmovdqu -0xa8(%rbp),%xmm12 0x000000000240066e: vmovdqu -0x98(%rbp),%xmm11 0x0000000002400676: vmovdqu -0x88(%rbp),%xmm10 0x000000000240067e: vmovdqu -0x78(%rbp),%xmm9 0x0000000002400683: vmovdqu -0x68(%rbp),%xmm8 0x0000000002400688: vmovdqu -0x58(%rbp),%xmm7 0x000000000240068d: vmovdqu -0x48(%rbp),%xmm6 0x0000000002400692: mov -0x38(%rbp),%r15 0x0000000002400696: mov -0x30(%rbp),%r14 0x000000000240069a: mov -0x28(%rbp),%r13 0x000000000240069e: mov -0x20(%rbp),%r12 0x00000000024006a2: mov -0x8(%rbp),%rbx 0x00000000024006a6: mov -0x18(%rbp),%rdi 0x00000000024006aa: mov -0x10(%rbp),%rsi ;; back to old(caller) stack frame: 0x00000000024006ae: add $0xd8,%rsp //栈顶指针复位 0x00000000024006b5: pop %rbp //栈底指针复位 0x00000000024006b6: retq
归纳出call_stub栈结构如下:

8.对于不同的Java方法,虚拟机在初始化时会生成不同的方法入口例程
(method entry point)来准备栈帧,这里以较常被使用的zerolocals方法入口为例,分析Java方法的栈帧结构与调用过程,入口例程目标代码的产生在InterpreterGenerator::generate_normal_entry()中:
(1).根据之前的分析,初始的栈结构如下:
获取传入参数数量到rcx中:
address InterpreterGenerator::generate_normal_entry(bool synchronized) { // determine code generation flags bool inc_counter = UseCompiler || CountCompiledCalls; // ebx: methodOop // r13: sender sp address entry_point = __ pc(); const Address size_of_parameters(rbx, methodOopDesc::size_of_parameters_offset()); const Address size_of_locals(rbx, methodOopDesc::size_of_locals_offset()); const Address invocation_counter(rbx, methodOopDesc::invocation_counter_offset() + InvocationCounter::counter_offset()); const Address access_flags(rbx, methodOopDesc::access_flags_offset()); // get parameter size (always needed) __ load_unsigned_short(rcx, size_of_parameters);
其中methodOop指针被保存在rbx中,调用Java方法的sender sp被保存在r13中,参数大小保存在rcx中
(2).获取局部变量区的大小,保存在rdx中,并减去参数数量,将除参数以外的局部变量数量保存在rdx中(虽然参数作为局部变量是方法的一部分,但参数由调用者提供,这些参数应有调用者栈帧而非被调用者栈帧维护,即被调用者栈帧只需要维护局部变量中除了参数的部分即可)
// rbx: methodOop // rcx: size of parameters // r13: sender_sp (could differ from sp+wordSize if we were called via c2i ) __ load_unsigned_short(rdx, size_of_locals); // get size of locals in words __ subl(rdx, rcx); // rdx = no. of additional locals
(3).对栈空间大小进行检查,判断是否会发生栈溢出
// see if we've got enough room on the stack for locals plus overhead. generate_stack_overflow_check();
(4).获取返回地址,保存在rax中(注意此时栈顶为调用函数call指令后下一条指令的地址)
// get return address __ pop(rax);
(5).由于参数在栈中由低地址向高地址是以相反的顺序存放的,所以第一个参数的地址应该是 rsp+rcx*8-8(第一个参数地址范围为 rsp+rcx*8-8 ~ rsp+rcx*8),将其保存在r14中
// compute beginning of parameters (r14) __ lea(r14, Address(rsp, rcx, Address::times_8, -wordSize))
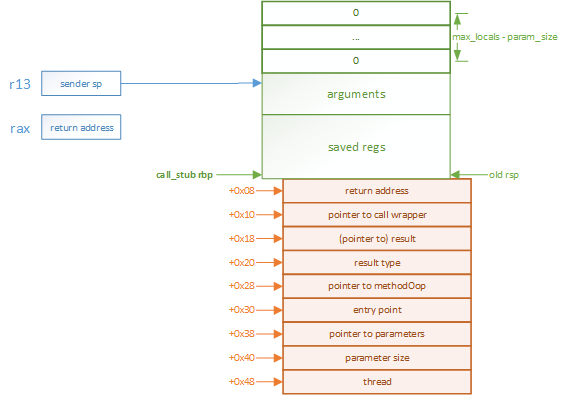
(6).为除参数以外的局部变量分配栈空间,若这些局部变量数量为0,那么就跳过这一部分处理,否则,将压入 maxlocals - param_size个0,以初始化这些局部变量
//该部分为一个loop循环 // rdx - # of additional locals // allocate space for locals // explicitly initialize locals { Label exit, loop; __ testl(rdx, rdx); __ jcc(Assembler::lessEqual, exit); // do nothing if rdx <= 0 __ bind(loop); __ push((int) NULL_WORD); // initialize local variables __ decrementl(rdx); // until everything initialized __ jcc(Assembler::greater, loop); __ bind(exit); }
这时栈的层次如下:
(7).将方法的调用次数保存在rcx/ecx中
// (pre-)fetch invocation count if (inc_counter) { __ movl(rcx, invocation_counter); }
(8).初始化当前方法的栈帧
// initialize fixed part of activation frame generate_fixed_frame(false);
generate_fixed_frame()的实现如下:
__ push(rax); // save return address __ enter(); // save old & set new rbp __ push(r13); // set sender sp __ push((int)NULL_WORD); // leave last_sp as null __ movptr(r13, Address(rbx, methodOopDesc::const_offset())); // get constMethodOop __ lea(r13, Address(r13, constMethodOopDesc::codes_offset())); // get codebase __ push(rbx);
保存返回地址,为被调用的Java方法准备栈帧,并将sender sp指针、last_sp(设置为0)压入栈,根据methodOop的constMethodOop成员将字节码指针保存到r13寄存器中,并将methodOop压入栈
} else { __ push(0); //methodData } __ movptr(rdx, Address(rbx, methodOopDesc::constants_offset())); __ movptr(rdx, Address(rdx, constantPoolOopDesc::cache_offset_in_bytes())); __ push(rdx); // set constant pool cache __ push(r14); // set locals pointer if (native_call) { __ push(0); // no bcp } else { __ push(r13); // set bcp } __ push(0); // reserve word for pointer to expression stack bottom __ movptr(Address(rsp, 0), rsp); // set expression stack bottom }
将methodData以0为初始值压入栈,根据methodOop的ConstantPoolOop成员将常量池缓冲地址压入栈,r14中保存着局部变量区(第一个参数的地址)指针,将其压入栈,此外如果调用的是native调用,那么字节码指针部分为0,否则正常将字节码指针压入栈,最后为栈留出一个字的表达式栈底空间,并更新rsp
最后栈的空间结构如下:

(9).增加方法的调用计数
// increment invocation count & check for overflow Label invocation_counter_overflow; Label profile_method; Label profile_method_continue; if (inc_counter) { generate_counter_incr(&invocation_counter_overflow, &profile_method, &profile_method_continue); if (ProfileInterpreter) { __ bind(profile_method_continue); } }
(当调用深度过大会抛出StackOverFlow异常)
(10).同步方法的Monitor对象分配和方法的加锁(在汇编部分分析中没有该部分,如果对同步感兴趣的请自行分析)
if (synchronized) { // Allocate monitor and lock method lock_method();
(11).JVM工具接口部分
// jvmti support __ notify_method_entry();
(12).跳转到第一条字节码的本地代码处执行
__ dispatch_next(vtos);
以上分析可能略显复杂,但重要的是明白方法的入口例程是如何为Java方法构造新的栈帧,从而为字节码的运行提供调用栈环境。
method entry point汇编代码的分析可以参考随后的一篇文章。

发表评论 取消回复